|
作者:人民中科研发中心张朝 摘要:在过去的很长时间里,计算机视觉领域依靠大规模的有标注数据集取得了很大的成功,特别是卷积神经网络的应用,使得视觉各子领域实现了跨越式发展,学术界和工业界开始投入大量的研究和应用,一度使大家相信,人工智能的大厦即将建成。然而,最近关于自监督学习(Self-supervised Learning,SSL)、Transformer、MLP等在学术界的研究成为热点,特别是Transformer和MLP的进击,大有要将监督学习和卷积结构拍死在沙滩上的节奏,作者相信,计算机视觉(CV)领域正在进入新的变革时代。 本文主要聚焦于CV领域自监督学习的相关内容,包含基本概念,与视觉各领域的关系和应用,以及当前的进展和一些思考,关于具体的自监督学习方法原理和技术有太多的文章进行解读,本文暂不涉及,力求从其他角度去观察自监督学习的特点和当前的局限性,分析总结经验,以求能给大家更多创新的想法启发。由于作者本人也有很大的局限性,一些观点不免有偏颇,还望各位大佬批评指正。 一、自监督学习介绍 AAAI2020会议上,Yann LeCun做了自监督学习的报告,表示自监督学习是人工智能的未来。从2019年底至今,MoCo系列,SimCLR,BYOL等一系列方法等井喷发展,通过无标注数据集达到了有标注数据集上的效果,几乎所有的下游任务都获得收益,使其成为了CV各领域的研究热门。自监督学习的优势,就是可以在无标签的数据上完成训练,而监督学习需要大量的有标签数据,强化学习需要与环境的大量交互尝试,数据为王的时代,此特点也使得大家充分相信自监督学习才是人工智能的发展方向。 自监督学习是与大家熟悉的监督学习和无监督学习的新名词,该类方法最早归类于无监督学习的范畴。关于自监督学习的概念,Paper with code[1]给出的定义是,使用无标注数据用自我监督的方式学习一种表示的方法,具体方式是通过学习一个替代任务(pretext task)的目标函数来获取特征表示。替代任务可以是一个预测类任务、生成式任务、对比学习任务。替代任务的监督信息来源是从数据本身获得的。举个栗子,替代任务可以是图片上色,图片抠图位置预测,视频帧顺序预测等。或者我们从结果反推方法,对于自监督来说,数据本身是没有标签的,我们需要通过自行设计任务来确定数据的标签。例如下图[2]中把图片中扣出9个块,让模型预测每个块的位置,对每个块自动构建标签的过程就是生成标签的过程,预测位置的工作就是替代任务。 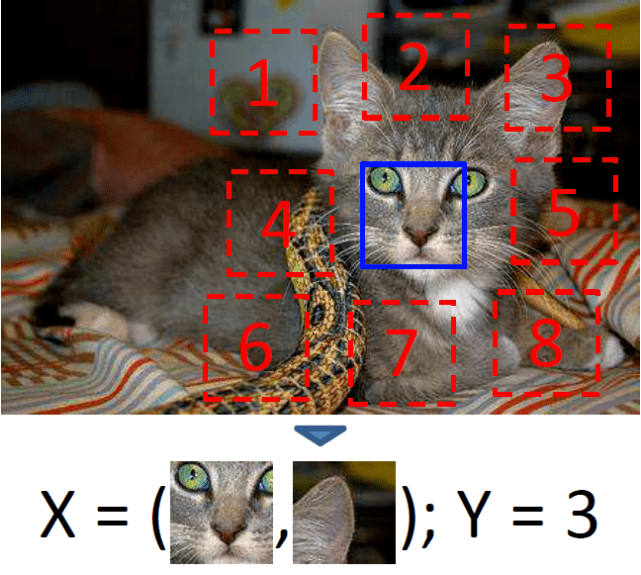
图1 图像块相对位置预测 近来热门且效果出色的自监督模型MoCo系列、SimCLR等,除去BYOL和SimSiam舍弃了负样本数据,基本都是采用正负样本对间对比的方式来构建,BYOL和SimSiam也构建了两个网络间的对比形式,都属于对比学习(Contrastive Learning)任务的范畴,可以说,当前的自监督学习的火热就是对比学习自监督方法的火热。其基本原理,是采用Siamese形式的网络结构,通过输入正负样本对数据,计算网络两个分支的输出的损失,以使网络能够学习到可以将相似样本拉近,不相似样本拉远的特征。自动构建标签的过程,就是常用的各种数据增强方法,如下图[3],原始图采用随机裁剪、颜色变换、模糊等方式构造相似样本对,而不同的原图或者增强后图像即是非相似样本对。训练得到的对比学习网络,在迁移到下游任务(分类、检测、分割)等数据集时,表现达到了可以媲美监督学习模型的效果。 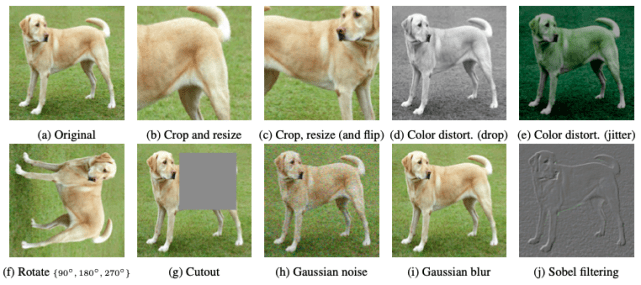
图2 SimCLR使用的数据增强方法 基于对比的自监督方法发展史如下图所示,选取了几个受关注较多的方法,时间截止2021年3月。Facebook和google两家研究团队神仙打架,对比学习框架逐渐去除掉一些技巧、结构,朝着中国哲学“大道至简”这一概念前进。 
图3 自监督对比学习发展历程 换一个角度思考,如果抛弃下游任务的finetune,只关注于替代任务的学习,那么自监督学习就像一个大染缸,各种替代任务只要可以构造出来,将其嵌入到自监督学习框架内,最终学习出来的特征和网络,就具有了替代任务的判别性。由此,就像使用魔法一样,我们就能够实现对神经网络能力的定制化改造。当前已经有不少研究成果发表,可以使用自监督完成帧序列预测、视频播放速度判断、图像旋转方向预测等。 二、自监督学习与其他领域的关系和思考 由于对比学习的强劲发展势头和其在自监督领域中占有的绝对比重,本文接下来直接以对比学习代替自监督学习的说法,在深挖对比学习框架过程中,发现其与CV的各领域其他方法如蒸馏学习、表示学习等有相似或关联之处,下面将逐个讨论。 1.对比学习和蒸馏学习 二者的网络结构形式非常相似,同样是双路网络结构,同样是对于最终的双路网络输出计算loss。不同的是,蒸馏学习往往是固定一个teacher网络,student网络规模要小于teacher,对比学习中,两个网络结构常常一致,并且是共同更新网络参数,蒸馏学习中teacher网络的参数固定。当然还有输入、loss、参数更新等不同,但蒸馏网络提供给了我们理解对比学习架构的另一种思考方式。在对比学习中常用的momentum update的更新方法和stop gradient技巧,可以理解成蒸馏学习的缓慢更新teacher版本和变体,由此我们可以将对比网络理解成双路网络互相学习,左右互搏。甚至,论文DINO[4]中将网络结构图中的两个分支直接写成了teacher和student。 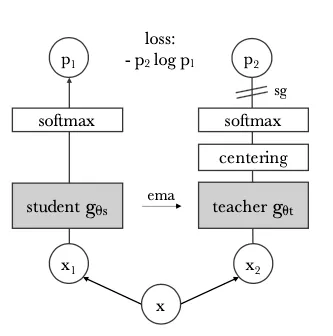
图4 DINO算法网络结构 2.对比学习和表示学习 对比学习属于表示学习的一种方法,通过对比学习获得的特征,迁移到下游任务中,进行finetune即可达到监督学习的效果,像极了早期CV领域的手工特征。对比学习的损失函数设置也是表示学习的出发点,相似样本在特征空间的距离依然相近,反之距离较远。监督学习网络也是学习到了很好的特征表示,才对我们的分类等任务有较好的表现。而现在对比学习要做的,就是在无标签的基础上,学习到一种泛化性更强的特征表示。可以预见的是,我们可以将对比学习模型替换掉imagenet预训练模型作为各类任务训练的起点,因为对比学习的训练集规模可以轻松超越imagenet,并且训练得到是超越分类任务的更具泛化的特征表示。 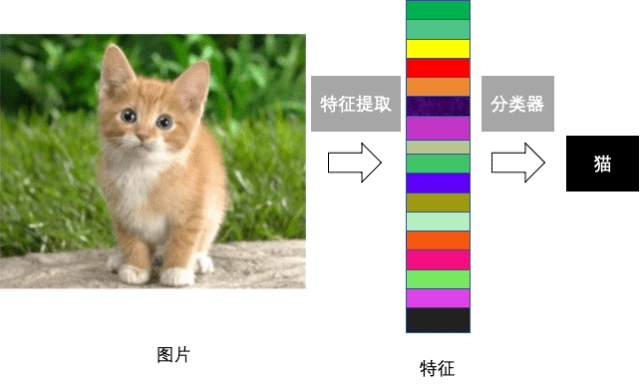
图5 监督学习的流程 3.对比学习和自编码器 自编码器也是无监督领域图像特征提取的一种方式,该方法基于一个编码器(encoder)将输入映射为特征,再通过解码器(decoder)将映射的特征恢复到原图,以减小重构误差为训练目标。 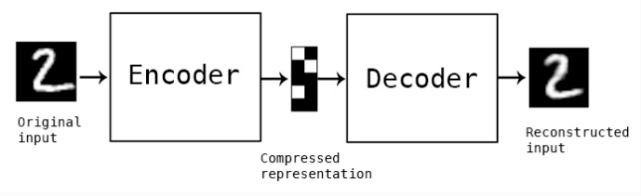
图6 自编码器网络结构示意 自编码器的编码过程可以看作是对比学习的单个分枝结构,二者的区别在于自编码器通过重构输出来作为自监督信息并避免平凡解,而对比网络是依靠两路网络的输出对比解决问题。从提取图片特征来看,对比学习直接对提取的特征做约束优化,保持了在嵌入空间中特征分布的Alignment(相似实例有相近的特征)和Uniformity(保留更多的信息,分布均匀)。此外,如果两种方式做一种结合也不失为一种可以尝试的方向,魔法不一定要打败魔法,两种魔法的加成也可能创造神奇的世界。 4.对比学习和自然语言处理 自然语言处理(NLP)领域自监督学习的成功,是对CV领域对比学习热潮的引领。词向量(Word2Vec)等方法的成功,在视觉领域能否成功复刻,驱动着大家向自监督视觉方向进行探索。 二者也有不同之处,单词或短语的数量是有穷的,而图片的数量则是无穷的,语句可以通过掩膜(mask)等方式构造出各种类型的变化,图片领域的变化如何高效地获得样本对并且有利于下游任务的效果提升都是要解决和优化的问题。也有各类简单的应用可以直接进行迁移,比如ALBERT[5]提出了句子顺序预测(SOP)任务可以直接迁移到视频片段的顺序预测上来。 5.对比学习和生成对抗网络(GAN) 问:对比学习和GAN还能扯上关系? 答:您好,有的。 请看来自于videoMoCo[6]文章的网络架构,其中,使用生成器作为相似样本对的生成方式,判别器就是对比学习的框架。可以说,GAN中的判别器分辨真假的任务和对比学习中的判别正负样本对的任务基本一致。 虽然videoMoCo在这里使用的生成器方式比较naive,但是给我们开阔了巨大的想象空间。对比学习的难点之一就是如何构造替代任务,当前各类对比学习方法都是采用机械的数据增强来完成,如果使用网络来完成正负样本对的标签生成,是不是能促进对比学习的效果提升,甚至扩大对比学习的应用范围。万物皆可对比,只要能够生成。 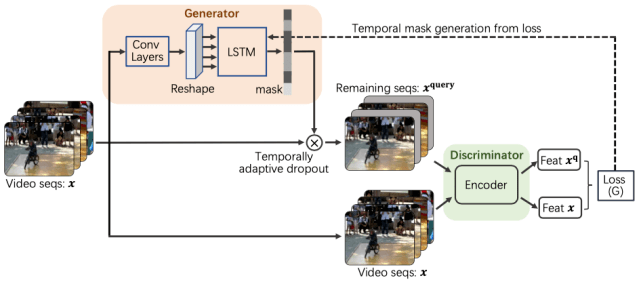
图7 videoMoCo算法网络结构 6.对比学习和度量学习、图像检索 通过与研究度量学习的同事交流,从相关网络算法和损失函数来看,对比学习和度量学习关系密切,或者直接看成是同一概念的两种称呼,目标都是使学习到的特征相似对象间距离小,不相似对象间距离大。现在对比学习领域大多使用InfoNCE损失函数,而度量学习用的多种损失还鲜有涉及,将这些损失引用过来也是有可能进一步优化的方向。 图像检索是我们尝试将对比学习作为实际应用的重要领域,对比学习可以天然地得到图像embeeding,并且也具有判别相似图像或者非相似图像的特点,在某些检索需求下,是完美的落地应用。我们也尝试过将对比学习模型和ArcFace训练的模型做对比,二者在embedding之后应用于图像检索中,简单验证的差异并不大,在模型适应性上,原始的数据增强多样性带来的影响更大。 三、对比自监督学习的发展趋势 1.化繁为简之路 大家在看之前的一些对比学习研究论文可能有一些疑惑,为什么stop gradient会起作用,momentum的作用具体是什么,好像并不是那么直观。后续方法中,momentum update被舍弃,负样本也可以舍弃,而Barlow Twins[7]则大开大合,舍弃各类奇技淫巧,将对比学习落实到最直观的互相关矩阵上,简洁到令人抓狂。反观各类方法和损失的根本归根结底就是互相关矩阵,互相关矩阵简洁的处理了样本对的采样方式,相比其他算法具有更高效的数据采样方式和数据规模,之前的各类方法就像在敌人的心脏周围不断挥舞,而Barlow Twins就好像剑客直刺到敌人的心脏。当然其采用的8192高维度的映射层也是值得讨论的问题。 负样本的数量对于特征的学习是十分重要的已经是对比学习中的共识。此方法以降低各特征维度的冗余为目标,换一个思考方式,咱们可以将互相关矩阵转换为批次内图像的相似矩阵,以此获得大规模的负样本数据以提升模型效果,不再受限于硬件的限制也能完成一个高效的对比模型训练。当然这种方法的先验假设就是,同一个批次内的图像,都是互为负样本对的。 损失函数的使用也有回归传统的意味,以下分别是Yann LeCun于2006年论文[13]中使用的损失函数和Barlow Twins的损失函数,你瞅瞅这俩损失像不像twins呢? 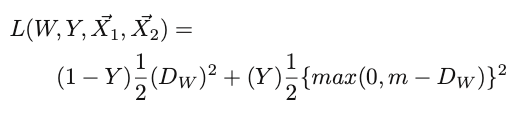
2006年提出的对比损失 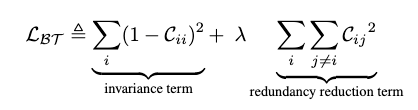
Barlow Twins使用的互相关矩阵对比损失 2.Transformer or MLP? 2021年4月初,陈鑫磊,何恺明等大神又发布了MoCo V3[8]版本的自监督方法,将Visual Transformers(ViT)引入到对比学习中来。4月底,DINO[4]论文发布,指出了自监督的ViT特征包含明显的语义分割信息,在有监督的ViT和卷积网络中都没有类似的表现。 
图8 DINO算法分割效果展示 在视觉领域,大有Transformer取代卷积网络的趋势,好像一个初出茅庐的年轻人乱拳打死老师傅。并且已经由简单的图像分类进攻到了自监督学习领域,还表现出了更厉害的特性,相信基于自监督的Transformer还会有更多的研究出现。 或者涅槃重生的MLP[9]等方法也可能在自监督领域大展身手,对应[9]的标题:MLP-Mixer: An all-MLP architecture for vision,自监督下的MLP方法题目我都想好了:An all-MLP Architecture for self-supervised Learning。 3.对比自监督在视频领域的应用 对比学习方法在视频领域的应用也有很多, [10]将不同播放速度的影片输入对比学习网络,训练模型用于播放速度判别;背景减除(Background Erasing [11]) 在视频每一帧中叠加当前视频中的随机帧,以达到减弱背景对于模型判断的影响,提高行为识别的准确性,网络输入为正常视频和叠加帧后视频;[12]对同一个视频采样不同的片段,将其看作是视频的数据增强即正样本对输入到网络中,获得视频特征的表示学习。 当前在视频领域的各种应用中,替代任务和下游任务一致的现象比较严重,造成模型只能对特定任务具有识别效果。同时,视频的特征的表示学习,照搬图像方法的现象明显,将2D卷积替换为3D卷积即可做迁移,相关研究还处于起步阶段,个人认为视频序列的特征提取可以针对其时间维度的特殊性做一些专门的工作。 视频表示学习的进步,必将推动视频检索领域的发展。在视频检索领域,可以通过自监督学习的方式构建检索以视频搜视频的检索方法,也可以做跨模态的视频检索,比如以文本搜视频,以语音搜视频等。反过来畅想,视频也可以生成文本、视频生成语音。 4.监督的对比学习 本来在自监督领域大放异彩的对比学习,还可以应用在监督学习领域,论文[14]做到了这一点。自监督领域中对比学习的依据是,两张图片是否同源,而和监督学习的结合,变成了两张图片是否同类。在使用监督对比损失后,获得了超过交叉熵的表现。 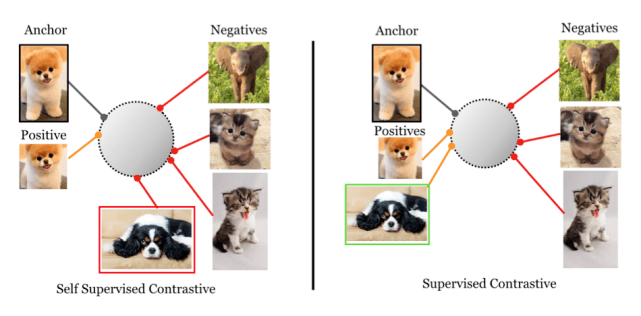
图9 自监督对比和监督对比 不过,该方法的核心还是采用了对比学习的方式训练了提取embedding的网络,而后将特征提取网络冻结,训练了全连接的分类网络。从本质上来讲,与自监督的网络迁移到下游任务是一致的。关键在于替代任务的构建,吸纳了有监督数据的信息。再次验证了自监督学习的魔法光环,也证明了对比损失相对于分类交叉熵损失,在提取有效特征方面的优秀能力。 四、一些思考 1.理论原理 尽管自监督学习取得了很好的效果,但其背后的数学原理和理论基本并没有特别扎实,大多通过实验结果反推模型结构和策略的效果,可能造成很多研究走了弯路,从理论基础出发,直达最终目标的效果可能会更好。 2.替代任务的构建 当前替代任务的构建特别是视频方向,多与下游任务为主导,没有特定的范式或者规则。替代任务所能完成的任务,就是自监督模型能完成任务的边界。替代任务的五花八门,导致各类任务的千差万别,没有办法比较性能优劣,只能是单纯的网络在另一个任务上的应用,当前图片领域多基于多种数据增强方法构建替代任务,而视频领域也可以提出统一的构建方式。 能够通过“半自动”方式做出来的替代任务少之又少,在各类的图像算法应用中,可能是影响自监督方法适应性的绊脚石。 3.能否构建直通下游任务的端到端学习 既然[4]中已经发现自监督中有明显的语义分割特征,在对比模型后端加入分割分支网络会不会对网络学习有帮助,抑或是直接训练得到可使用的分割网络,都是值得研究的问题。 4.除对比的其他形式构建特征提取网络 本质上,对比网络是除去常规网络之外,训练得到特征表示的一种方式而已,与前文提到的自编码器有异曲同工之妙。对比学习的成功在于,其训练得到的特征提取网络,在下游任务中表现优异,也是所提特征有效的表现。由此我们可以得到启发,还有没有其他的形式构建训练网络,也能够提取得到有效特征。相信新模式的提出肯定也会和对比学习一样,引领一波研究浪潮。 5.广阔天地,大有可为 自监督学习还处于探索阶段,有很多可以深入探究的部分,相信无论在学术界和工业界自监督学习都会有广泛的应用。作为深度学习中的一种魔法,还需要更多的人来挖掘其潜能,创造更多的神迹。 总结 本文针对当前热门的自监督学习领域在CV领域的研究,梳理了其与其他CV的相同和不同点,以及几个前沿研究点的探讨。希望通过本文,大家对自监督学习的有个更加明确的定位,如果对于您的研究和思路有些许帮助,将是作者的更大欣慰。 ————————————————————————————————— 人民中科(济南)智能技术有限公司是由人民网与中科院自动化所共同建设的“智能技术引擎”和“人才创新平台”,聚焦音视频内容理解技术,围绕“内容理解+行业应用”,提供多形态的内容理解算法技术、软件系统、硬件装备等,向各行业输出专业的AI技术解决方案。 参考文献: [1] https://www.paperswithcode.com/task/self-supervised-learning [2] Doersch C, Gupta A, Efros A A. Unsupervised visual representation learning by context prediction[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1422-1430. [3] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607. [4] Caron M, Touvron H, Misra I, et al. Emerging properties in self-supervised vision transformers[J]. arXiv preprint arXiv:2104.14294, 2021. [5] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[J]. arXiv preprint arXiv:1909.11942, 2019. [6] Pan T, Song Y, Yang T, et al. Videomoco: Contrastive video representation learning with temporally adversarial examples[J]. arXiv preprint arXiv:2103.05905, 2021. [7] Zbontar J, Jing L, Misra I, et al. Barlow twins: Self-supervised learning via redundancy reduction[J]. arXiv preprint arXiv:2103.03230, 2021. [8] Chen X, Xie S, He K. An empirical study of training self-supervised visual transformers[J]. arXiv e-prints, 2021: arXiv: 2104.02057. [9] Tolstikhin I, Houlsby N, Kolesnikov A, et al. MLP-Mixer: An all-MLP architecture for vision[J]. arXiv preprint arXiv:2105.01601, 2021. [10] Wang J, Jiao J, Liu Y H. Self-supervised video representation learning by pace prediction[C]//European Conference on Computer Vision. Springer, Cham, 2020: 504-521. [11] Wang J, Gao Y, Li K, et al. Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning[J]. arXiv preprint arXiv:2009.05769, 2020. [12] Feichtenhofer C, Fan H, Xiong B, et al. A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning[J]. arXiv preprint arXiv:2104.14558, 2021. [13] Hadsell R, Chopra S, LeCun Y. Dimensionality reduction by learning an invariant mapping[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). IEEE, 2006, 2: 1735-1742. [14] Khosla P, Teterwak P, Wang C, et al. Supervised contrastive learning[J]. arXiv preprint arXiv:2004.11362, 2021. 小程序长列表渲染优化 Nat. Commun. |
|
 主页 > 新闻 >
主页 > 新闻 >